Serial Correlation Test Statistic
Jun 23, 2013 This video explains how it is possible to adapt the t tests for serial correlation for the presence of endogenous regressors. This corrected test when.
Discovering the Point Biserial. In this article, we define one of the most commonly used statistics in educational assessment, namely the point-biserial coefficient.
Durbin–Watson statistic
Computing and interpreting the Durbin–Watson statistic. If e t is the residual associated with the observation at time t, then the test statistic is.
In statistics, the Durbin–Watson statistic is a test statistic used to detect the presence of autocorrelation a relationship between values separated from each other by a given time lag in the residuals prediction errors from a regression analysis. It is named after James Durbin and Geoffrey Watson. The small sample distribution of this ratio was derived by John von Neumann von Neumann, 1941. Durbin and Watson 1950, 1951 applied this statistic to the residuals from least squares regressions, and developed bounds tests for the null hypothesis that the errors are serially uncorrelated against the alternative that they follow a first order autoregressive process. Later, John Denis Sargan and Alok Bhargava developed several von Neumann–Durbin–Watson type test statistics for the null hypothesis that the errors on a regression model follow a process with a unit root against the alternative hypothesis that the errors follow a stationary first order autoregression Sargan and Bhargava, 1983. Note that the distribution of this test statistic does not depend on the estimated regression coefficients and the variance of the errors. 1
Contents
1 Computing and interpreting the Durbin–Watson statistic
2 Durbin h-statistic
3 Durbin–Watson test for panel data
4 Implementations in statistics packages
5 See also
6 Notes
7 References
8 External links
Computing and interpreting the Durbin–Watson statistic edit
If et is the residual associated with the observation at time t, then the test statistic is
where T is the number of observations. Note that if one has a lengthy sample, then this can be linearly mapped to the Pearson correlation of the time-series data with its lags. 2 Since d is approximately equal to 2 1 r, where r is the sample autocorrelation of the residuals, 3 d 2 indicates no autocorrelation. The value of d always lies between 0 and 4. If the Durbin–Watson statistic is substantially less than 2, there is evidence of positive serial correlation. As a rough rule of thumb, if Durbin–Watson is less than 1.0, there may be cause for alarm. Small values of d indicate successive error terms are, on average, close in value to one another, or positively correlated. If d 2, successive error terms are, on average, much different in value from one another, i.e., negatively correlated. In regressions, this can imply an underestimation of the level of statistical significance.
To test for positive autocorrelation at significance α, the test statistic d is compared to lower and upper critical values dL,α and dU,α :
If d dL,α, there is statistical evidence that the error terms are positively autocorrelated.
If d dU,α, there is no statistical evidence that the error terms are positively autocorrelated.
If dL,α d dU,α, the test is inconclusive.
Positive serial correlation is serial correlation in which a positive error for one observation increases the chances of a positive error for another observation.
To test for negative autocorrelation at significance α, the test statistic 4 d is compared to lower and upper critical values dL,α and dU,α :
If 4 d dL,α, there is statistical evidence that the error terms are negatively autocorrelated.
If 4 d dU,α, there is no statistical evidence that the error terms are negatively autocorrelated.
Negative serial correlation implies that a positive error for one observation increases the chance of a negative error for another observation and a negative error for one observation increases the chances of a positive error for another.
The critical values, dL,α and dU,α, vary by level of significance α, the number of observations, and the number of predictors in the regression equation. Their derivation is complex statisticians typically obtain them from the appendices of statistical texts.
If the design matrix of the regression is known, exact critical values for the distribution of under the null hypothesis of no serial correlation can be calculated. Under the null hypothesis is distributed as
img class tex entry-content-asset alt
frac
sum_ i 1 n-k nu_i xi_i 2
sum_ i 1 n-k xi_i 2,
src https://upload.wikimedia.org/math/3/f/1/3f10627bff65ab630cf98351e61d50a4.png
{kind=link}
where n are the number of observations and k the number of regression variables; the are independent standard normal random variables; and the are the nonzero eigenvalues of img class tex entry-content-asset alt
mathbf I - mathbf X mathbf X T mathbf X -1 mathbf X T mathbf A,
src https://upload.wikimedia.org/math/3/6/4/364bc6aea33bfc9d84b975ab0b668327.png where is the matrix that transforms the residuals into the statistic, i.e. . 4 A number of computational algorithms for finding percentiles of this distribution are available. 5
{kind=link}
Although serial correlation does not affect the consistency of the estimated regression coefficients, it does affect our ability to conduct valid statistical tests. First, the F-statistic to test for overall significance of the regression may be inflated under positive serial correlation because the mean squared error MSE will tend to underestimate the population error variance. Second, positive serial correlation typically causes the ordinary least squares OLS standard errors for the regression coefficients to underestimate the true standard errors. As a consequence, if positive serial correlation is present in the regression, standard linear regression analysis will typically lead us to compute artificially small standard errors for the regression coefficient. These small standard errors will cause the estimated t-statistic to be inflated, suggesting significance where perhaps there is none. The inflated t-statistic, may in turn, lead us to incorrectly reject null hypotheses, about population values of the parameters of the regression model more often than we would if the standard errors were correctly estimated.
If the Durbin–Watson statistic indicates the presence of serial correlation of the residuals, this can be remedied by using the Cochrane–Orcutt procedure.
It is important to note that the Durbin–Watson statistic, while displayed by many regression analysis programs, is not applicable in certain situations. For instance, when lagged dependent variables are included in the explanatory variables, then it is inappropriate to use this test. Durbin s h-test see below or likelihood ratio tests, that are valid in large samples, should be used.
Durbin h-statistic edit
The Durbin–Watson statistic is biased for autoregressive moving average models, so that autocorrelation is underestimated. But for large samples one can easily compute the unbiased normally distributed h-statistic:
using the Durbin–Watson statistic d and the estimated variance
of the regression coefficient of the lagged dependent variable, provided
Durbin–Watson test for panel data edit
For panel data this statistic was generalized as follows by Alok Bhargava et al. 1982 :
If ei, t is the residual from an OLS regression with fixed effects for each panel i, associated with the observation in panel i at time t, then the test statistic is
This statistic can be compared with tabulated rejection values see Alok Bhargava et al. 1982, page 537. These values are calculated dependent on T length of the balanced panel time periods the individuals were surveyed, K number of regressors and N number of individuals in the panel. This test statistic can also be used for testing the null hypothesis of a unit root against stationary alternatives in fixed effects models using another set of bounds Tables V and VI tabulated by Alok Bhargava et al. 1982.
Implementations in statistics packages edit
R: the dwtest function in the lmtest package, durbinWatsonTest or dwt for short function in the car package, and pdwtest for panel models in the plm package. 6
MATLAB: the dwtest function in the Statistics Toolbox.
Mathematica: the Durbin–Watson d statistic is included as an option in the LinearModelFit function.
SAS: Is a standard output when using proc model and is an option dw when using proc reg.
EViews: Automatically calculated when using ols regression
Stata: the command. estat dwatson, following. regress in time series data. 7 Engle s LM test for autoregressive conditional heteroskedasticity ARCH, a test for time-dependent volatility, the Breusch–Godfrey test, and Durbin s alternative test for serial correlation are also available. All except -dwatson- tests separately for higher-order serial correlations. The Breusch–Godfrey test and Durbin s alternative test also allow regressors that are not strictly exogenous.
Excel: although Microsoft Excel 2007 does not have a specific Durbin–Watson function, the d-statistic may be calculated using SUMXMY2 x_array,y_array /SUMSQ array
Minitab: the option to report the statistic in the Session window can be found under the Options box under Regression and via the Results box under General Regression.
Python: a durbin_watson function is included in the statsmodels package statsmodels.stats.stattools.durbin_watson
SPSS: Included as an option in the Regression function.
See also edit
Time-series regression
ACF / PACF
Correlation dimension
Notes edit
Chatterjee, Samprit; Simonoff, Jeffrey 2013. Handbook of Regression Analysis. John Wiley Sons. ISBN 1118532813.
Gujarati 2003 p. 469
Durbin, J.; Watson, G. S. 1971. Testing for serial correlation in least squares regression.III. Biometrika 58 1 : 1–19. doi:10.2307/2334313.
Farebrother, R. W. 1980. Algorithm AS 153: Pan s procedure for the tail probabilities of the Durbin-Watson statistic. Journal of the Royal Statistical Society, Series C 29 2 : 224–227.
Hateka, Neeraj R. 2010. Tests for Detecting Autocorrelation. Principles of Econometrics: An Introduction Using R. SAGE Publications. pp. 379–82. ISBN 978-81-321-0660-9.
regress postestimation time series Postestimation tools for regress with time series PDF. Stata Manual.
References edit
Bhargava, Alok; Franzini, L.; Narendranathan, W. 1982. Serial Correlation and the Fixed Effects Model. Review of Economic Studies 49 4 : 533–549. doi:10.2307/2297285.
Durbin, J.; Watson, G. S. 1950. Testing for Serial Correlation in Least Squares Regression, I. Biometrika 37 3–4 : 409–428. doi:10.1093/biomet/37.3-4.409. JSTOR 2332391.
Durbin, J.; Watson, G. S. 1951. Testing for Serial Correlation in Least Squares Regression, II. Biometrika 38 1–2 : 159–179. doi:10.1093/biomet/38.1-2.159. JSTOR 2332325.
Gujarati, Damodar N.; Porter, Dawn C. 2009. Basic Econometrics 5th ed.. Boston: McGraw-Hill Irwin. ISBN 9780073375779.
Kmenta, Jan 1986. Elements of Econometrics Second ed.. New York: Macmillan. pp. 328–332. ISBN 0-02-365070-2.
Neumann, John von 1941. Distribution of the ratio of the mean square successive difference to the variance. Annals of Mathematical Statistics 12 4 : 367–395. doi:10.1214/aoms/1177731677. JSTOR 2235951.
Sargan, J. D.; Bhargava, Alok 1983. Testing residuals from least squares regression for being generated by the Gaussian random walk. Econometrica 51 1 : 153–174. JSTOR 1912252.
Verbeek, Marno 2012. A Guide to Modern Econometrics 4th ed.. Chichester: John Wiley Sons. pp. 117–118. ISBN 978-1-119-95167-4.
External links edit
Table for high n and k
Econometrics lecture topic: Durbin–Watson statistic on YouTube by Mark Thoma
Retrieved from https://en.wikipedia.org/w/index.php.title Durbin–Watson_statistic oldid 691526266
Categories: EconometricsStatistical testsTime series analysis.

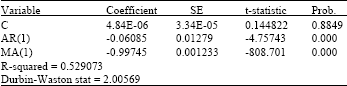
- The Durbin-Watson DW statistic is used in a test for serial correlation of residuals i.e., error terms in several types of regression models.
- 170 Testing for serial correlation 3.1 Options pecies that the output from the rst-differenced regression should be dis-output s played. By default, the first.
- 35 as a regressor. EViews User s Guide, p 273 This test is an alternative to the Q-Statistic for testing for serial correlation. It is available.
- Feb 20, 2014 This video explains the intuition behind the Durbin-Watson test of serial correlation, and compares it with the t test introduced in the previous video.
- Independence of Residuals - Durbin-Watson Statistic. The next assumption is that the residuals are not correlated serially from one observation to the next.